

You ran your survey campaign and got back the results. Now what? How do you get actionable insights out of the data? Surveys are essential to learning more about your current or potential customers or any group and audience. Surveys can also help you review and evaluate past events. There are a lot of simple tools like Google Forms or TypeForm to create your survey and make it easy for the participants to fill it out. The real challenge is figuring out to get insights from the survey results and how to apply what you have learned from the survey.
In this article, you will master how to analyze survey results.
Revisiting the questions
Before we jump into the nitty-gritty of survey analysis, let’s spend just a little time on what type of data you have or might have in your survey based on the responses.
What was the goal of your survey?
To get real insights, you need to think of what your intent was at the beginning. What was the main reason you created the survey?
What type of questions do you have?
In a survey, you can ask the respondents two types of questions. One is the close-ended question. Close-ended questions are when you have pre-populated answers options that the respondents can choose. In this article, we are focusing on close-ended questions because they produce quantifiable results and thus are easier to analyze.
Open-ended questions, on the other hand, don’t have predefined answers. The respondents need to provide feedback and share their opinions in their own words. The data you get from this type of question is qualitative. You need to look into every answer separately to learn more about them.
What type of data do you have?
To get an overall picture of your survey results, you need to look at the different types of data you collected. Types of data you can have:
- Numeric data
- Categorical data
- Ordinal data
- Date-time
AnswerMiner automatically detects the type of your data, making the analysis easier. It displays the type of each column in the header in the Smart Data view, or as a summary, you can read it in the Dataset Overview.
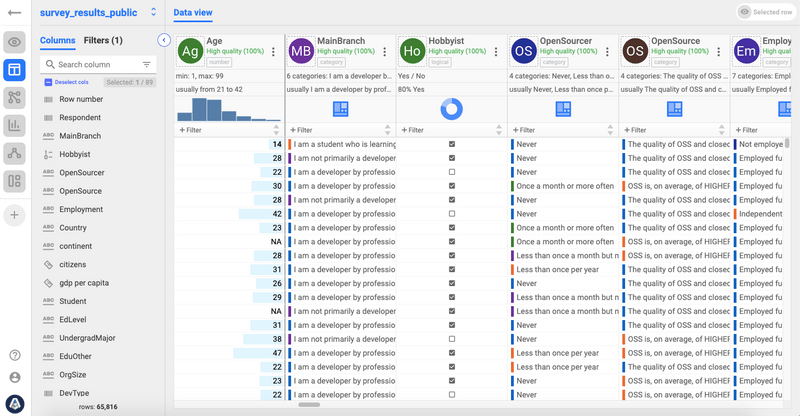
The data type is also essential to know what kind of statistical methods can you apply for calculating correlations. However, AnswerMiner does it automatically, so you don’t have to worry about it.
Starting steps in survey analysis
Filtering
By filtering, you will narrow down your focus to specific parts of your data. For example, you can filter by answers and see only replies that are within the specified range or using demographic parameters by focusing on a specific city, country, gender, or age.
Clustering - creating groups
In a survey analysis, clustering refers to the process of grouping similar answers or respondents together. By grouping people together, who gave the same answers to one or multiple survey questions, the correlation between these people will be higher. Thus, you can conclude. After creating these clusters, you will see some structures in the data, but you still need to figure out why those structures exist. By giving a name for the groups can be an excellent way to describe and differentiate them.
Creating groups can also be done by a scatter plot where a categorical variable is used to color the plots. See it demonstrated in the following example. The data is the well known Pima Indians Diabetes dataset behind the chart, that you can also download to play with it.
The chart shows the relationship between Glucose and BMI colored by if the person has diabetes Yes/No.
Basic statistical analysis
There is some fundamental statistical analysis that you can do to get a big picture of your data:
- Average and median. The average is the sum of all the numbers, divided by the number of numbers in the set. The median is the middle point of an ordered list of numbers. If you calculate the average and median for a specific question, you will get an overall view of what your respondents replied. But you need to create clusters to have a more in-depth look. Also, keep in mind that outliers have a significant effect on the average. The median will give you a better understanding of the data.
- Distribution (Histogram, Bubble Chart). With a distribution chart, you can discover the frequency of specific answers to get a high-level view or the replies. Also, you can use distribution charts to find outliers in your data. While using AnwerMiner, don’t forget to check the “include outliers” box, so that they will be displayed on the visualization. Outliers are filtered out by default settings.
Relations in your survey data
Correlation vs. causation
A correlation refers to the degree of association between two variables in a dataset. In our case, between two survey items. It is a positive correlation when you observe that increasing one variable; the other one increases as well. Or when one decreases, the other one decreases as well. A negative correlation is when one increases, and the other one decreases or vice versa.
A correlation doesn’t mean one always causes the other. When you analyze your survey data, there might be a lot of correlations, but not all of them are causations. Meaning, the two things might happen at the same time, but one is not causing the other. It might simply be just a coincidence.
How to find correlations?
You can find correlations by comparing two variables in your data set. For example, select two questions from your survey that you think might correlate with each other. Then, filter your data only to see the replies to these questions. Finally, look for a correlation between the two. If one value is higher, the other one is higher as well? That’s a positive correlation. If one value is decreased, the other one is increased? That’s a negative correlation.
With the relation matrix feature in Answerminer, finding correlations in your data is a breeze.
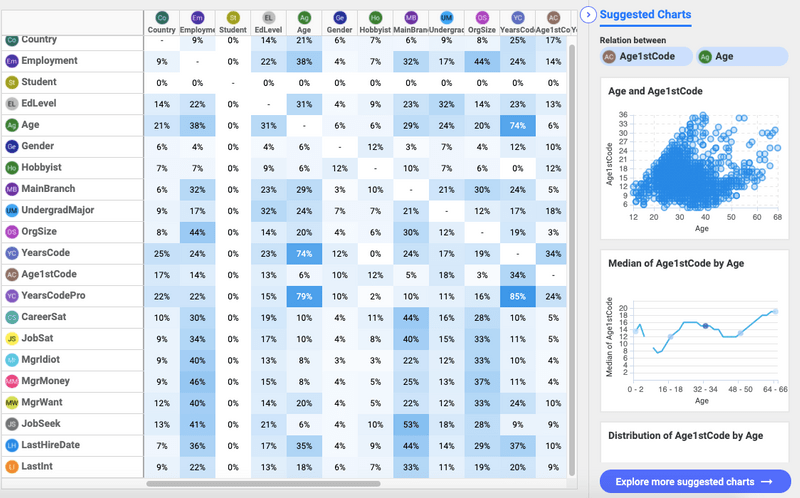
Answerminer shows you the strength of correlation between each data column, so you just have to pick those that interest you the most. By clicking on the cells in the matrix, visualizations will pop-up which will show the correlation on charts.
This is the chart from the previous image where the actual age of the respondents and their age when first time coding compared on a scatter plot.
How to interpret analysis results (examples)
Now, let’s see actual examples of how you can analyze survey data. The dataset we’re going to analyze is the Stackoverflow developer survey 2019, containing 85 questions and more than 88 thousand responses. This survey is about getting a big picture of people who are coding all around a world, including their favorite technologies, job preferences, education level and employment status.
Distribution and description of the respondents.
Countries
Most of the respondents are from the United States and India. There are 180 countries included in this dataset, so it almost covers the whole world.
Employment
As you can see on this bubble chart most of the respondents (72.5%) are full time employees. The second largest group is the independent contractors around 10%.
Education level
Distribution of categorical data, just like education level, can be visualized in a Donut or a Column chart. If you prefer a Donut chart, it is better to have a maximum of 4-5 slices. In this case, we have ten categories, so some of them will be grouped as “Others.”
Donut chart
In a column chart, you can visualize all the categories.
Column chart
As the charts show most of the IT professionals have a Bachelor degree (44%), but many of them have Master (22%)
Comparison and relation analysis.
Analyzing survey results became interesting when two or more variables compared to each other, or the relationship between them is showing some trends. In the previous paragraph, only one variable was examined, which is excellent to understand the structure of the data, but there is a lot more to explore.
As a first step let’s see how employment relates to age or other variables.
Some people are not employed, or there is no data about it. They are most likely students, so to see a clearer picture of employment and age, we have to exclude (filter out) students from the analysis.
Median of age by employment (students excluded)
Genders
The IT industry is labeled as represented by men, so it is an interesting question to answer, which are the countries where women are higher represented than men. (Students are still excluded)
There are more than two options in this case for the Gender question, as can be seen on the following chart.
Based on that information (7% are women), we would like to see which are the countries where this rate is higher.
In the following chart, the top 30 countries are shown based on the number of responses. There are some countries where the number of responses was so low that they would not help us with this question. If you would like to see the woman rate of the respondents for each country in this dataset, you can check it on this visualization.
Multiple correlation analysis with the prediction tree
In the previous examples, we only compared two variables, but there can be more, which are correlating with our target, which in this case is gender=woman. The following example shows how to describe the respondents of this survey who are women, based on their answers.
They mostly use Instagram, and they don’t consider themselves as a member of the Stack Overflow community, and they don’t code as a Hobby. If all of the above is true the chance of a respondent’s gender is woman increases to 54.05%
Even if they are Hobbyists, the probability is still higher than 7%.
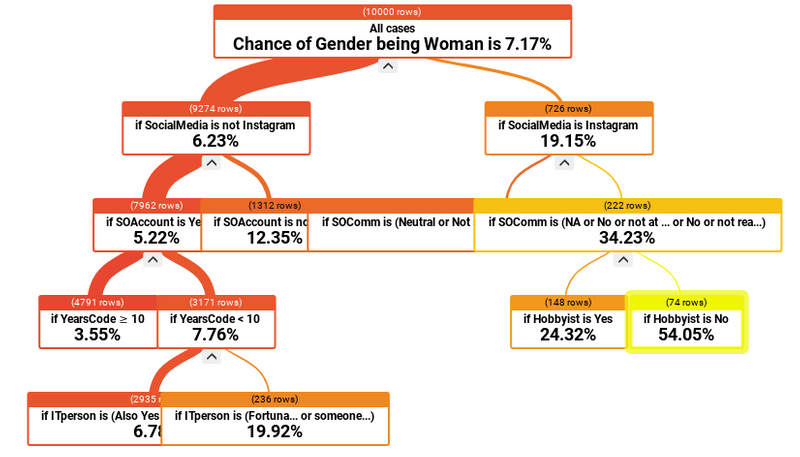
The other path is worth following, where the year of experience is included as a predictor. For that, the following has to be fulfilled.
The most used social media platform is not Instagram, and they have a Stack Overflow account, and they have less than ten years of experience, and they are not the IT person of their family. In this case, the chance is almost 20%.
Statistical significance
Statistical significance is meant to show us whether we can consider something true. When you consider your survey results statistically significant, you know that the results you get from it are likely trustworthy. The main factor in statistical significance is the number of respondents. It does matter how many people filled out your survey. In the example we used in this article, we wanted to analyze a dataset that includes enough data to draw relevant visualizations.
Visualizing Survey Analysis
A crucial part of survey analysis is visualization. Without proper data visualization, it’s difficult to find useful information in your survey results that moves the needle. You need an easy-to-use data visualization tool that lets you focus on what matters the most to you: making better decisions based on survey results.
In the previous paragraph, you could see some visualizations made with AnswerMiner. As a person who is analyzing survey data, you don’t need to know how to code or create visualizations by your hands. AnswerMiner will take care of all of it so you can focus on telling the story of your analysis.
Get started today!
