

Even if you created the most accurately designed survey, you WILL find errors in the answers. To err is human— so to speak. But the process of data cleansing or data cleaning can help you to bring the best out of your collected data. So let’s find the errors, repair the broken values, and process the data correctly by using the methods presented in this article.
Why Do I Need Data Cleaning?
The data cleanup process is important because of the errors associated with the data collection process. Some sources contain blank inputs and errors that may occur in the data. From an industrial viewpoint, particular collection technologies, like sensors, are inherently inaccurate due to the hardware limitations associated with collection and transfer. Sometimes sensors can skip readings due to a hardware failure or a low battery. Scanning technologies may contain errors associated with optical character recognition technology, which is far from perfect.
From a customer-centered perspective, users may not want to provide the requested information or intentionally enter incorrect values. For example, it has been observed that users sometimes enter the wrong date of birth on auto-registration sites, like social networks. Another problem is mistyping because a significant amount of data is entered in this field by hand. When something is done manually there’s a higher chance for typos.
Last but not least, by doing a data cleaning you can early detect outliers in your data that may be crucial in further processing. So do not make a mistake by promptly throwing away suspicious data, always explore it first.
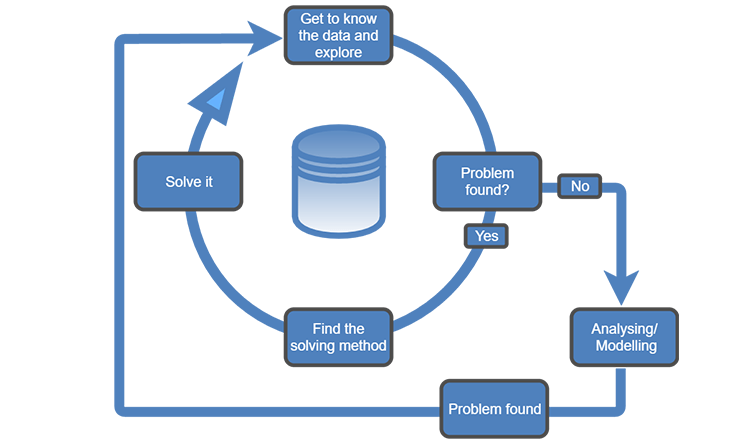
Just Before You Dive In
A good data set starts with a good setup: in most cases with a good survey. Create a well-structured and logical schema to make your later work easier. Use closed questions that can be answered with numbers or with a simple YES or NO.
For the scaling method, forget about the common 1 to 5 scaling, otherwise, most of your answers will be 3, as everybody just wants to skip through the questions. Use more likely the Likert scale, where there is no middle value, the scores are from 1 to 4. Let only one answer per question to make your job easier. Even for powerful statistical software, it is hard to separate multiple answers.
Now it is only the formatting left. In most cases, your file format will be XLS, SQL, or other. For further preparation, you have to change this to CSV or TXT as most of the data analyzer tools are reading this format. If the CSV is not comma-separated, use your Notepad’s “Source & Change All” command to turn all necessary characters to comma separators.
Now you can start the cleaning process by the following methods.
How to Perform Data Cleaning?
In the era of big data, data cleaning methods are becoming more important than ever. Methods are required to remove and correct missing or incorrectly entered data. Many data inputs can remain indeterminate due to irregularities in data collection or the inherent nature of the data. Such missing inputs could be approximated, and the process of approximation is also called imputation.
In cases where the same information is available from multiple sources, inconsistencies can be detected. The data that is inconsistent with the distribution of the remaining data is often noisy and should be removed. It is also possible to occur that users give alternate answers to the same question by not giving attention before. Trimming this wrong information needs time and attention.
Data can often be presented on different scales (e.g. years, days, etc.). This can cause some features to be inadvertently overestimated, so other features are implicitly ignored. Therefore, it is important to normalize the different features.
There is an interesting source of failure caused by regional differences. In some countries, the decimal comma is used over decimal points. Always keep in mind the origin of your data set and if needed, transform the values according to your computer’s OS default settings.
Several open-source tools enable you to perform data cleaning and preparation: Jasper, Rattle, RapidMiner, Orange, TrifactaWragner, Talend Data preparation, etc.
“In Data Science, 80% of time spent prepare data, 20% of time spent complain about need for prepare data.” @BigDataBorat
Removing duplicates
Duplicated data records often occur during data collection: combining datasets from multiple sources, scraping data from the web, receiving data from clients, or other departments. For example, two records have the same ID, or when the same article has been scraped multiple times. Duplicated records should be removed.
Dropping out irrelevant data
Delete records that are not relevant to others or belong to another table. Here, you should also review your charts from exploratory data analysis. Checking for irrelevant data before starting the analysis can prevent many problems later on.
Fixing syntax errors
Fix typos and inconsistent capitalization. Strings sometimes have mistakes because any kind of value can be a string, technically. Also, strings can have extra spaces, which should be cut removed. Tools like AnswerMiner remove them automatically.
Type conversion
Make sure that numbers are stored as numerical data types, a date is stored as a date object, text as string, and so on. Category units can be converted into numbers if needed. If there are values that you cannot convert to the specified type, you should convert them to NA. If you want to analyze correlation later, you need numeric data for doing so. Make sure you changed all the necessary fields to numeric values.
Standardization
Ensure that all string values are either lower or upper case. For numerical values, ensure that all values have the same measurement unit. The task is to convert the value to one single unit. For example, the length should be either in meters, or centimeters (not both). The same applies if you use inches and feet. For dates, the U.S. format is different from the European format. Recording the date as timestamp is different from recording the date as a date object. All these should be unified.
Normalization
In some cases, you should scale your data, so that it fits within a specific range, like 0–100 or 0–1. This will help you in making some data types easier to plot.
For example, you need to reduce the imbalance in your plots (when having many outliers). The most common functions to be applied are: log, square root, and inverse. The normalization also rescales the values into a range of 0–1, but its goal is to transform the data so it’s normally (Gaussian) distributed.
How Do I Handle Outliers and In-Record Errors?
Outliers are values that are significantly different from all other data points. You shouldn’t remove outliers until you prove that there is a good reason for that. For example, you may notice some strange, suspicious values that are unlikely to happen and decide to remove them. Some models, like linear regression or statistical numbers like the mean are sensitive to outliers so that outliers might throw the model off from where most of the data lie. Always have in mind that some extreme value can be real legitimate data. Investigate and explore this kind of data before removing it.
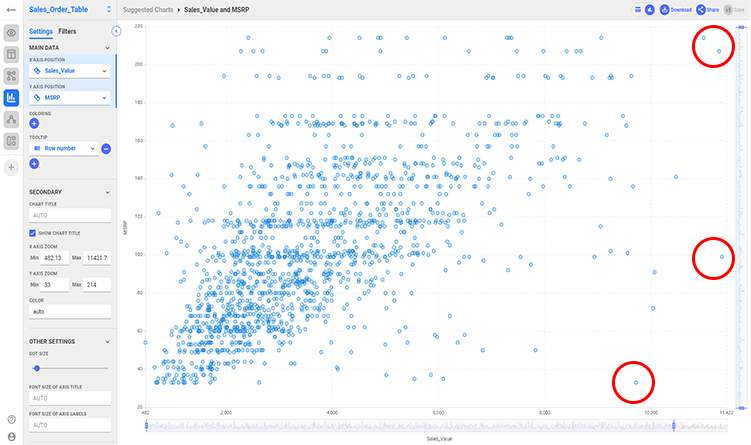
What Can I Do with Missing Values?
Missing data can be a problematic issue in machine learning. You can’t ignore missing values in your database. You should handle them in some way since many algorithms do not accept missing values. There are three approaches you can undertake to handle the missing data:
- Insert values in the missing places. You can insert some statistical value, e.g. mean or median of the data. You can also insert values that are taken from similar records.
- Drop only if you are comfortable losing the whole record or whole column.
- Flag the missing data. You can assign value 0 to the missing numerical values (and skip these entries in the analysis) and assign the value “Missing” for categorical data fields.
Conclusion
After cleaning, the dataset should be consistent with the other data sets in the process. A summary statistics about the data, called data profiling, can be done to provide general info about the data quality. For example, checking whether a particular column complies with a particular standard or pattern.
You should verify the data correctness by re-checking the data and ensuring they function. For example, if you fill in the missing data, they might disrupt some of the rules and constraints. It could require some manual correction, if not possible otherwise.
Also, reporting about the data should be done after the cleaning. Most of the software tools can generate reports of the changes made, which rules were disrupted, and how many times.
Data cleaing is a time-consuming task, but also a critical one. It is impossible to get insights from the data without proper cleaning first. Once all the data that are relevant to the data mining process are collected and cleaned - their transformation and reduction begin, so the analysis can be performed.
